基因谷
記得去年「阿爾法狗」(AlphaGo)的新聞出來後,小編曾下定決心要跨專業學習一下AI,看看它能否在咱們生物領域也掀起熱浪。結果當小編剛剛了解到阿爾法狗的命脈乃來自Deep Learning (深度學習)真傳時,它的親兄弟「AlphaFold」
就以迅雷不及掩耳之勢(2018年12月初召開新聞發布會)在蛋白質摺疊預測領域獨領風騷。有生物學背景的我們都知道,雖然科學家們破譯了基因組,但從DNA到蛋白質翻譯過程受各種基因和/或蛋白質的調控、修飾,並且蛋白質從翻譯產生到能發揮功能的這一過程也是在細胞內經歷了各種修飾、摺疊。但人家「AlphaFold」則不畏這些千難萬苦,「硬生生」的通過胺基酸序列直接預測蛋白質的3D結構(AlphaFold
的新聞發布連結:https://deepmind.com/blog/alphafold/)。所以當「AlphaFold」一出世,大家都驚呼它是能把諾貝爾獎抱回家的人選之一。
既然「AlphaFold」和「AlphaGo」是親兄弟,那它們兩個到底有什麼相同點呢?其實這個相同點就是Deep Learing算法。而不同點則在於該算法分別應用在了圍棋領域和蛋白質研究領域。所以,無論是學生物的,還是學物理的,還是學化學的小童鞋們是時候學習一下Deep Learing算法,說不定你就是下一個諾貝爾獲獎者呢!如果你還沒有這個意識,那小編告訴你,學Deep
Learing的專家和學者已經進軍到生物領域的各個方向了。
我們QB期刊向來提倡交叉,尤其是計算、數學、物理等領域與生命科學的交叉,並且我們也一直在跟蹤、刊登這些交叉領域的前沿熱點文章。在Deep Learning這個火熱階段,我們編輯部特別邀請到了該領域的曾堅陽教授和裴劍鋒教授作為QB期刊2018年第四期的Guest Editors,為我們組織了一場關於Deep Learning或Neural
Network在第三代測序分析鹼基識別、藥用蛋白預測中應用和線粒體形態定量分析的「盛宴」(感興趣的小夥伴可以登陸我們網站先睹為快哈,網站地址為:https://link.springer.com/journal/40484,或直接在百度中搜索「Quantitative Biology」,進入期刊的網站首頁),接下來的一段時間內小編將一一與大家分享。
今天先給大家分享的是Deep Learning在MinION測序儀base-calling中的應用1(WaveNano:a signal-level nanopore base-caller via simultaneous prediction of nucleotide labels and move labels through bi-directional
WaveNets,點擊文末「閱讀原文」進入文章主頁,可免費下載全文)。
這篇文章是來自沙特阿卜杜拉國王科技大學(KAUST)的Xin Gao教授團隊與香港中文大學(深圳)的Zhen Li 博士合作完成。 Xin Gao 教授團隊目前已經完成了一系列與納米孔測序相關的工作。該團隊關於Deep Learning在MinION測序儀數據模擬器中的工作(DeepSimulator: a deep simulator for Nanopore
sequencing)於今年9月份發表在了生物信息學領域老牌期刊Bioinformatics上的哦2。此外,該團隊還完成了一款全新的cwDTW算法,可以高效的聯配超長的納米孔信號,並以此為基礎進行信號標註(signal labeling)從而能夠檢測單核苷酸多態性(SNP)3。該工作在國際頂級生物信息學會議ECCB
2018上口頭展示,同時亦發表於Bioinformatics。在這裡向Xin Gao教授及其團隊表示祝賀!
英國生物技術公司OxfordNanopore自2014年推出MinION測序儀後,由於其小巧的身材(iphone大小),要求不高的運行環境,較長的reads讀取(超過15kb),較快的測序速度,實時的測序數據監測等特點,一經問世就受到廣泛關注。該測序儀於2016年登上了國際太空站(ISS),完成了第一次太空測序,並證實了對Lambda phage的測序結果在ISS和地球上並無差別4。
MinION測序儀的基本工作原理是基於納米孔測序技術,通過檢測單鏈DNA分子通過納米孔時引起電流變化的不同,用於鹼基的識別(見Figure 1)。由於電流檢測的頻率通常是DNA序列通過納米孔速度的7-9倍,因此這對base-calling造成巨大的技術挑戰。此外,較高的測序錯誤率,尤其是對indels(插入和缺失)的測序,是納米孔測序儀面臨的一個主要問題。
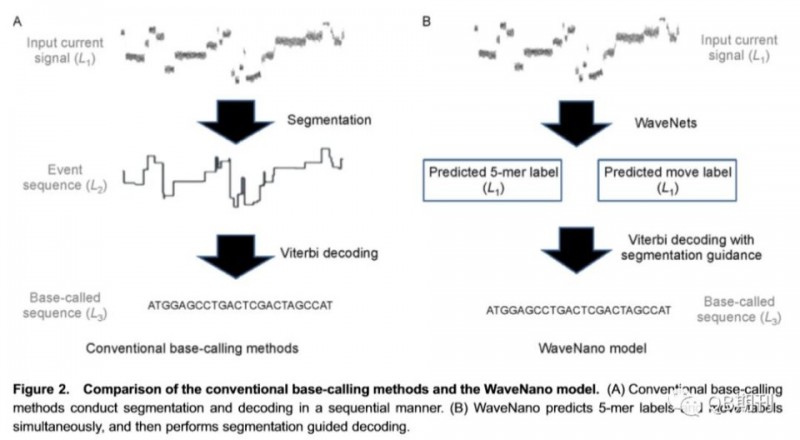
為了解決納米孔測序儀較高錯誤率的問題,目前已經出現了多種算法。這些算法可以簡單地歸為兩類,即基於機器學習(Machine Learning)的算法和基於共有序列(Consensus)的算法。這兩種算法的基本原理都是通過serial base-calling過程(見Figure 2A)進行鹼基識別,而這一過程勢必會增加錯誤率。此外,這兩種算法所用到的機器學習中的模型建構(Model
Architecture)更適用於短片段的計算。為了解決上述問題,本文作者們採用了Google DeepMind團隊在語音合成和語音識別方面新開發的具有完美表現的WaveNets深度學習方法5將納米孔中的信號當作語音信號,而base-calling則類似於語音識別過程,開發了一種基於機器學習的新算法-WaveNano(見Figure 2B和Figure
3)。這種算法不依賴任何segmentations/decoding工具,而完全是一種self-contained 的線下工具。
通過該算法,文章作者對Lambdaphage的基因組用MinION進行了測序,結果得到了大約24,000個reads,電流信號平均為63,000bp。同時,作者還將WaveNano與官方的Metrichor算法以及Albacore算法進行了結果比較(如Table1),結果表明WaveNano不僅能預測比較準確的DNA序列,同時該算法對indel的處理結果明顯優於Metrichor和Albacore。此外,WaveNano的運行時間約為1個信號序列為0.5s,而Albacore的運行時間則為2s。
由此可見,WaveNano算法對於分析MinION產生的Lambda phage測序結果具有良好的表現,尤其對於indel序列的分析,其結果要比目前商用的Metrichor和Albacore具有更高的準確度。
Reference
Sheng Wang, Zhen Li,Yizhou Yu and Xin Gao. (2018) WaveNano:a signal-level nanopore base-caller viasimultaneous prediction of nucleotide labels and move labels throughbi-directional WaveNets.
Quant. Biol., 6 (4): 359-368.
YuLi, Renmin Han, Chongwei Bi, Mo Li, Sheng Wang, Xin Gao. (2018) DeepSimulator:a deep simulator for Nanopore sequencing. Bioinformatics, 34 (17), 2899-2908
Renmin Han, Yu Li, Xin Gao, Sheng Wang. (2018)An accurate and rapid continuous wavelet dynamic time warping algorithm forend-to-end mapping in ultra-long nanopore sequencing. Bioinformatics, 34
(17),i722-i731
Castro-Wallace,S. L., Chiu, C. Y., John, K. K., Stahl, S. E., Rubins, K.H.,McIntyre, A.B.R.,Dworkin, J.P.,Lupisella, M.L., Smith, D. J., Botkin, D. J., et al. (2017)Nanopore DNA sequencing and
genome assembly on the International Space Station.Sci. Rep., 7, 18022
VanDen Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A.,Kalchbrenner, N., Senior, A., and Kavukcuoglu K. (2016) Wavenet: A generativemodel for raw audio. ArXiv,
1609.03499